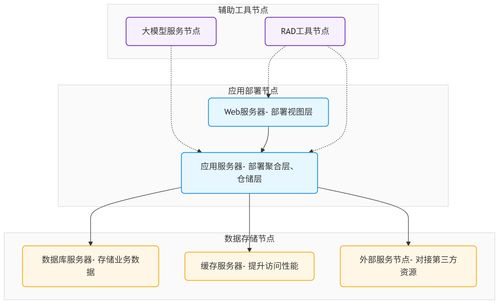
在當今數據爆炸的時代,企業面臨著前所未有的挑戰:如何在海量數據洪流中,實現毫秒級的實時分析與決策?傳統基于磁盤的存儲和計算架構,因其固有的I/O延遲,已難以滿足對即時性要求極高的金融交易、物聯網監控、在線推薦等場景。內存計算(In-Memory Computing, IMC)應運而生,它如同一條鋪設于數據世界中的“高速公路”,通過將數據持久保存在系統的主內存(RAM)中進行處理,徹底繞過了磁盤瓶頸,為海量數據的實時處理與智能存儲支持服務提供了革命性的解決方案。
一、 內存計算:速度的本質突破
內存計算的核心理念是將整個數據集或工作集載入到集群服務器的內存中。與從機械硬盤或固態硬盤(SSD)讀取數據相比,從內存中訪問數據的速度要快幾個數量級(通常為納秒級 vs. 毫秒級)。這種速度的本質突破,使得復雜的數據查詢、事務處理和高級分析能夠在瞬間完成,實現了真正的“實時”響應。
二、 構建海量數據實時處理的高速公路
- 消除瓶頸,暢通無阻:傳統數據處理流程中,CPU等待磁盤I/O是主要性能瓶頸。內存計算將數據置于CPU的“近鄰”,使得數據處理不再受限于緩慢的存儲介質,計算資源得以被最大化利用,數據處理流水線從此暢通無阻。
- 并行架構,規模擴展:現代內存計算平臺(如Apache Ignite, SAP HANA, Hazelcast等)通常采用分布式架構。數據被分區并存儲在多臺服務器的內存中,計算任務可以并行執行。這不僅支撐了海量數據的處理能力,還通過橫向擴展(增加節點)實現了近乎線性的性能提升,確保“高速公路”能夠隨著車流(數據量)的增加而拓寬。
- 支持復雜分析與事務一體化:這條“高速公路”并非單一車道。它能夠同時支持高并發的在線事務處理(OLTP)和復雜的在線分析處理(OLAP),即HTAP模式。企業可以在同一份實時數據上既運行日常交易,又進行深度數據挖掘和預測分析,無需在系統間進行耗時且易錯的數據抽取、轉換和加載(ETL)。
三、 對數據處理與存儲支持服務的賦能
內存計算不僅關乎速度,它更重塑了數據服務的模式:
- 實時決策與體驗:在金融風控中,實時偵測欺詐交易;在電商場景,基于用戶實時行為進行個性化推薦;在物聯網中,即時監控設備狀態并預警。這些都依賴于內存計算提供的亞秒級分析能力。
- 智能存儲與緩存層:內存計算系統常作為高性能的分布式緩存或主數據庫層。它可以作為后端傳統數據庫(如Oracle, MySQL)的加速層,緩存熱點數據,承擔大部分讀和計算負載,同時通過持久化機制確保數據安全。這種架構為現有存儲系統提供了強大的性能支持服務。
- 流批一體處理:結合流處理引擎(如Apache Flink, Spark Streaming),內存計算平臺能夠對持續流入的數據流進行實時計算和狀態維護,并將結果即時更新到內存數據網格中,供其他服務查詢,實現了流處理與批處理的無縫融合。
- 簡化技術棧,降低總擁有成本(TCO):通過整合多個數據庫和分析系統的功能,內存計算平臺有助于簡化企業龐雜的數據技術棧,減少數據移動和冗余,從而降低運維復雜性和總體成本。
四、 挑戰與未來展望
盡管前景廣闊,內存計算也面臨挑戰。其一是成本,大容量內存比磁盤昂貴;其二是數據持久化,需要結合磁盤、SSD或非易失性內存(NVM)來防止斷電數據丟失。隨著內存價格的持續下降、NVM技術的成熟以及云服務商提供內存優化型實例,這些障礙正被逐步克服。
內存計算將與人工智能、邊緣計算更深度地融合。在邊緣側進行實時數據處理和推理,在云端進行全局協同與模型訓練,內存計算構成的數據處理“高速公路網”將更加高效和智能,成為數字經濟不可或缺的核心基礎設施。
****
內存計算已不再是尖端的概念,而是正在落地賦能千行百業的實踐技術。它構建的高速數據處理通道,正將海量數據從負擔轉化為實時價值的源泉,深刻變革著企業的運營、決策與創新模式,為邁向數據驅動的實時智能時代奠定了堅實的基礎。